Messages, serialization and other things
I remember one time a colleague told me, something like this: "My boss said, that the one manage the string, it handles everything". Taken out of context, it may seem pretentious, but do not you get the feeling that most of the programming is reduces to "manipulation"?
And if you stop to think, today, is not it reduced to communication? To the shipment of "messages"? And that’s where I want to get in this article, to the famous serialization and deserialization.
I did not get to experience it, but when I started in the Java world, there was still talk of Corba and RMI. I’m not going to stop much, for that we have the wikipedia, but the first let’s say it served to communicate separate and distinct systems, and the second more "close".
To what if it arrives, and went to the world to SOAP. If we look back, the "XML was invented" at 1998, I even remember doing an interview in my beginnings for the "xml company". And in XML, SOAP is based on the transmission of messages. Here begins to stop side the "binary" messages to move to XML, with its supposed advantages, and disadvantages. Because parsing and loading into XML memory was expensive, agile because you could access any part of the message, but expensive.
I do not extend more here, just remember DTD, XSD, XSLT, and a series more than acronyms related to the XML world.
But people got tired of the XML soon, in 2000 came the REST. People were tired of schemes, of rigidity, the new millennium wanted flexibility, browsers wanted to be able to find what they wanted, without having to load everything.
Let’s say that the REST, brought the JSON, a format where the "tabulation" gave the format, and there was no need for so much label, which reduced the size of the messages, but hey, it was still necessary to parse them.
At that time, Google started using Protocol Buffer internally, a binary specification language. The same thought that in the end, either It made a lot of sense that the messages were "human-readable", and even if I could there is compression of an XML message in a superior layer, in the end it is effort to serialize and deserialize in a "human-readable" way was not an obstacle either to not put one field after another.
On the other hand, the piramide REST it began to evolve.
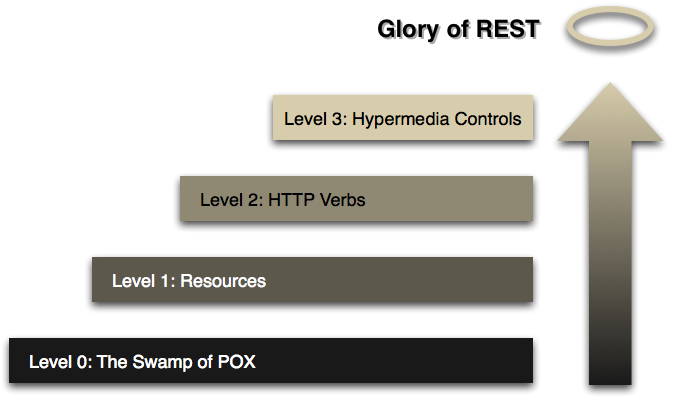
And things started to appear like: Swagger and RAML, that end up merging at OPENAPI and things like: Hateoas, Json Schema, even GraphQL, which to be the query language that we know, part of a language of definition of structures.
In the end, in the Java world, and I suppose that in the rest of languages also, all Transmission requires serialization and deserialization (which may be more or less complex).
For example, the transmission of a large XML to a destination, where it only interests you certain data of the same, does not have to serialize it in memory to make a On the DOM, a parser can be used stax to look for what is needed, and it does not matter the size of the XML, it will take more or less the same, because the overhead is produced when it is loaded into memory.
In the case of a JSON, those who need their specified getter / setter, the parsers that simply load in hash, those that use the reflection, those that they do not use it (because the user codes a certain part), those that "precompile" code, those who …
In the end, in this world of programming, you can never think that you know everything, and in IMHO you can always improve, doing things differently.
If we dive a little, we can find some benchmarks. For example in this comparatories on libraries we can discover the large number of JSON libraries that exist, and their different performance, proof that you can always evolve, and when you reach the physical limits, you can always do it in another way. In this other comparativa inclyendo protobuf do the analysis, focusing on the number of attributes, of the class to be serialized, and they make some interesting considerations of the transformations that pass "below", away from the sight of our eyes, commenting on changes between JDK 8 and 9.
-
dsl-json Use a dsl to generate the parser.
-
jsoniter Precompiling a parser.
-
jackson-afterburner Evolution of the well-known library.
-
usando graavl A more theoretical approach using Graavl.
What if we talk about bbdd NSQL or document-oriented ?, as for example CouchBase …?
In the end, here using the java API, there is also a serialization / deserialization, in the end what is saved is a document, which must (according to API) serialize more or less.
In this repo, I have messed around a little with some ideas.
-
It is clear that the smaller the entity to persist, the sooner it will persist.
-
But not by inserting it into smaller pieces (related to each other) Insert before.
-
Both for insertions and queries, if a string is inserted, without going through JPA can earn 50% (discounting the serialization to String, remember that arrives in String format from synchro) and 90% in reading approx.
-
A .findOne in spring data jpa, will always be slower than a native one. Does the view on the entity type add a delay?
-
Network latency from the server to the bbdd also counts, less data, faster.
-
The servers with SSD vs HDD for bbdd nosql show large differences in performance.
It depends on the use and the problem that you want to address, it can not always make sense, serialize to have the "objects" accessible, but let’s use them.
As an exercise for home
According to the benchmark if will change the implementation of JsonConverter from Jackson to Jsonite, could win 30% in the part that the spring data library jpa passes from the object to com.couchbase.client.java.document.json.JsonObject.
Make a pull request to implement serializacion of couchbase with jsoniter and see if it’s faster than the standard, and not much less than with the sdk java
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Email