Mensajes, serialización y otras cosas
Recuerdo una vez que un compañero me dijo, algo así: "Mi jefe decía, que el que maneje los string, lo maneja todo". Sacada fuera de contexto, puede que parezca pretencioso, pero ¿no os da la sensación que la mayor parte de la programación se reduce a la "manipulación"?
Y si os paráis a pensar, hoy día, ¿no se reduce al las comunicación? ¿al envío de "mensajes"? Y ahí es donde quiero llegar en este artículo, a la famosa serialización y deserialización.
Yo no llegue a vivirlo, pero cuando empezaba en el mundo del Java, todavía se hablaba de Corba y RMI. No me voy a detener mucho, para eso tenemos la wikipedia, pero el primero digamos servía para comunicar sistemas separados y distintos, y el segundo mas "cercanos".
A lo que si llegue, y de lleno fue al mundo SOAP. Si echamos la vista atras, el "XML se invento" en 1998, hasta recuerdo haber echo alguna entrevista en mis inicios para la "xml company". Y en XML se basa SOAP para la transmisión de mensajes. Aqui empieza a dejarse de lado los menajes "binarios" para pasar al XML, con sus supuestas ventajas, y desventajas. Porque parsear y carga en memoria XML era costoso, ágil porque podías acceder a cualquier parte del mensaje, pero costoso.
No me extiendo mas aquí, simplemente recordar DTD, XSD, XSLT, y una serie mas de siglas relacionadas con el mundo XML.
Pero la gente se canso pronto del XML, en el 2000 llego el REST. La gente estaba cansada de esquemas, de la rigidez, el nuevo milenio quería flexibilidad, los navegadores querían poder buscar lo que quisieran, sin tener que cargarlo todo.
Digamos que el REST, trajo el JSON, un formato donde la "tabulación" daba el formato, y no hacia falta tanta etiqueta, con lo que se reducía el tamaño de los mensajes, pero bueno, seguía haciendo falta parsearlos.
Por aquella época Google empieza a usar internamente Protocol Buffer, un lenguaje de especificación binario. Lo mismo pensaban que al final, tampoco tenia mucho sentido que nos mensajes fueran "human-readable", y aunque pudiera existir compresión de un mensaje XML en una capa superior, al final es esfuerzo de serializar y deserializar de una manera "human-readable" tampoco era óbice para no poner un campo detrás de otro.
Por otro lado, la piramide REST empezó a evolucionar.
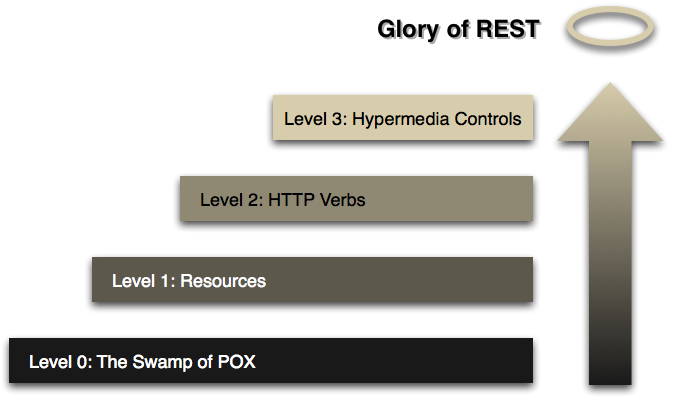
Y empezaron a aparecer cosas como: Swagger y RAML, que terminan fusionandose en OPENAPI y cosas como: Hateoas, Json Schema, incluso GraphQL, que para ser el lenguaje de consulta que conocemos, parte de un lenguaje de definición de estructuras.
Al final, en el mundo Java, y supongo que en el resto de lenguajes tambien, toda transmisión requiere una serialización y una deserialización (que pueden ser mas o menos complejas).
Por ejemplo, la transmisión de un XML grande a un destino, donde solo le interese ciertos datos del mismo, no tiene porque serializarlo en memoria para hacer un recorrido sobre el DOM, puede usarse un parser stax para buscar lo que se necesita, y da igual el tamaño del XML, tardara mas o menos igual, pues el overhead se produce cuando se carga en memoria.
En el caso de un JSON, los que necesitan sus getter/setter especificados, los parser que simplemente carga en hash, los que usan la reflexion, los que no la usan (porque el usuario codifca cierta parte), los que "precompilan" codigo, los que…
Al final, en este mundo de la progracion, no se puede pensar nunca que se sabe todo, y en IMHO siempre se puede mejorar, haciendo las cosas de otra forma.
Si buceamos un poco, podemos dar con algunos benchmark. Por ejemplo en esta comparativas sobre librerias podemos descubir la gran cantidad de librerias JSON que existen, y su diferente performance, prueba de que siempre se puede evolucinar, y cuando se llegan a los limites fisicos, siempre se puede hacer de otra forma. En esta otra comparativa inclyendo protobuf hacen el analisis, enfocando a la cantidad de atributos, de la clase a serializar, y hacen algunas consideraciones interesantes de las transformaciones que pasan "por debajo", lejos de la vista de nuestros ojos, comentando cambios entre JDK 8 y 9.
-
dsl-json Usa un dsl para generar el parser.
-
jsoniter Precompilan un parser.
-
jackson-afterburner Evolucion de la conocida librería.
-
usando graavl Un enfoque mas teórico usando Graavl.
¿Y si hablamos de las bbdd NSQL u orientadas a documento?, como por ejemplo CouchBase…
Al final, aqui usando el API java, tambien existe una serializacion/deserializacion, al final lo que se guarda es un documento, que debe (segun API) serializarse mas o menos.
En este repo, he trasteado un poco con algunas ideas.
-
Esta claro que cuanto mas pequeño sea la entidad a persistir, antes se persistirá.
-
Pero no por insertarlo en trozos mas pequeños (relacionados unos con otros) se inserta antes.
-
Tanto para inserciones como consultas, si se inserta un string, sin pasar por JPA puede ganarse un 50% (descontado la serializacion a String, recordar que ya llega en formato String desde sincro) y un 90% en lectura aprox.
-
Un .findOne en spring data jpa, siempre va a ser mas lento que uno nativo. ¿La vista sobre el tipo de entidad añade un retardo?
-
La latencia de red desde el servidor a la bbdd tambien cuenta, menos datos, mas veloz.
-
Los servidores con SSD vs HDD para bbdd nosql muestran grandes diferencias de rendimiento.
Depende del uso y el problema que se quiera abordar, no siempre puede tener sentido, serializar para tener los "objetos" accesibles, sino vamos a usarlos.
Como ejercicio para casa
Segun los benchmark si se cambiara la implementacion de JsonConverter de Jackson a Jsonite, podria ganarse un 30% en la parte que la libreria spring data jpa pasa del objeto a com.couchbase.client.java.document.json.JsonObject.
Hacer una pull request para implementar serializacion de couchbase con jsoniter y ver si es mas rapido que el estandar, y no mucho menos que con la sdk java
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Email